May 2, 2023 | 5 minute read
Manjesh HB
Data Scientist, SofTronicLabs
Overcoming Overfitting in Decision Trees: A Deep Dive into Limiting Maximum Depth
May 2, 2023 | 5 minute read
Data Scientist, SofTronicLabs
In the realm of predictive modeling, decision trees are a widely used tool for their interpretability and versatility. However, decision trees are prone to overfitting, where the model learns the specific patterns and noise of the training data rather than the underlying true patterns. This results in a model that performs exceedingly well on the training data but poorly on unseen data. In this blog post, we'll delve into the overfitting issue with decision trees and explore effective techniques to mitigate it, focusing on "Limiting Maximum Depth" and "Minimum Samples per Leaf."
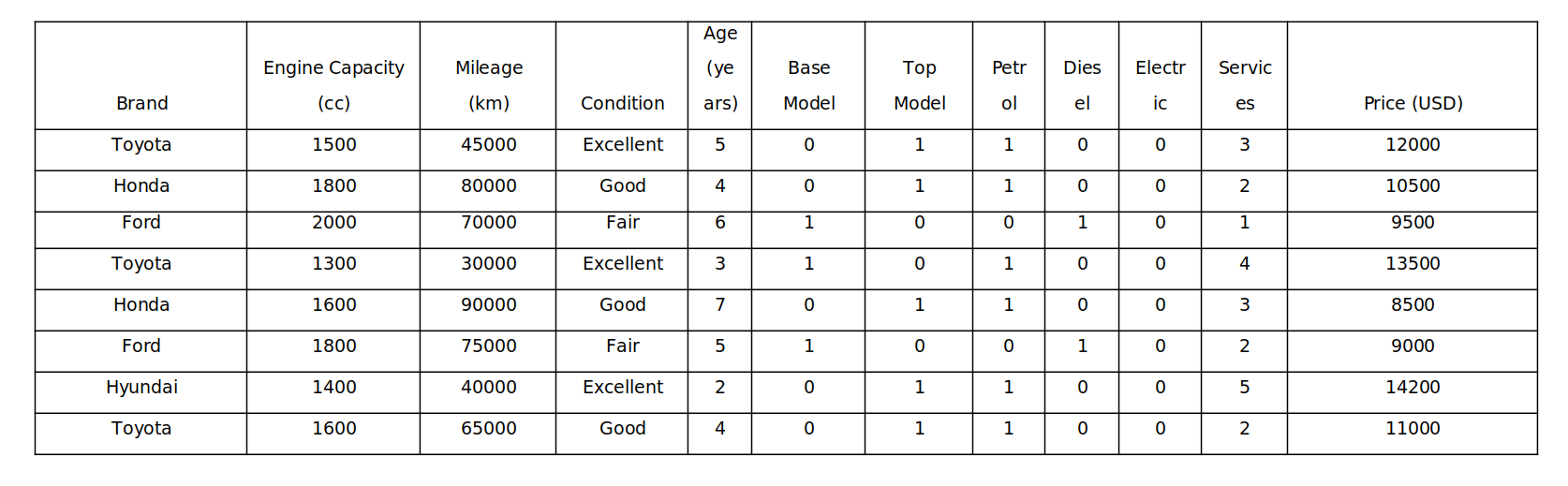
Sample Dataset:
For our demonstration, we'll use a simplified dataset comprising features like brand, engine capacity, mileage, condition, age, and services, along with the actual price in USD for second-hand cars.
Understanding Overfitting:
Overfitting is a critical challenge in machine learning models, including decision trees. It occurs when the model excessively fits the noise and intricacies of the training data, failing to capture the fundamental underlying patterns. In the context of our dataset, overfitting can result in overly complex decision trees that fail to generalize well to unseen data.
Training a Regression Decision Tree:
The steps for training a regression decision tree are similar to those for classification, with slight differences in the evaluation criteria and label assignment
1. Data Collection:
With the example of above simple dataset with information on second-hand cars, including features and actual price values.
2. Data Preprocessing:
Clean and preprocess the data, handling missing values, encoding categorical variables, and splitting the data into training and validation sets.
3. Choosing the Splitting Criteria:
For regression, the splitting criteria often use metrics like Mean Squared Error (MSE) or Mean Absolute Error (MAE) to minimize the error between predicted and actual prices.
4. Splitting the Data:
The algorithm selects the best feature to split the data based on the chosen error metric.
5. Recursive Splitting:
It continues splitting the data recursively, creating child nodes based on the chosen features.
6.Assigning Labels:
In regression, each leaf node is assigned a label representing a numerical value, which is typically the mean or median of the actual prices in that leaf node.
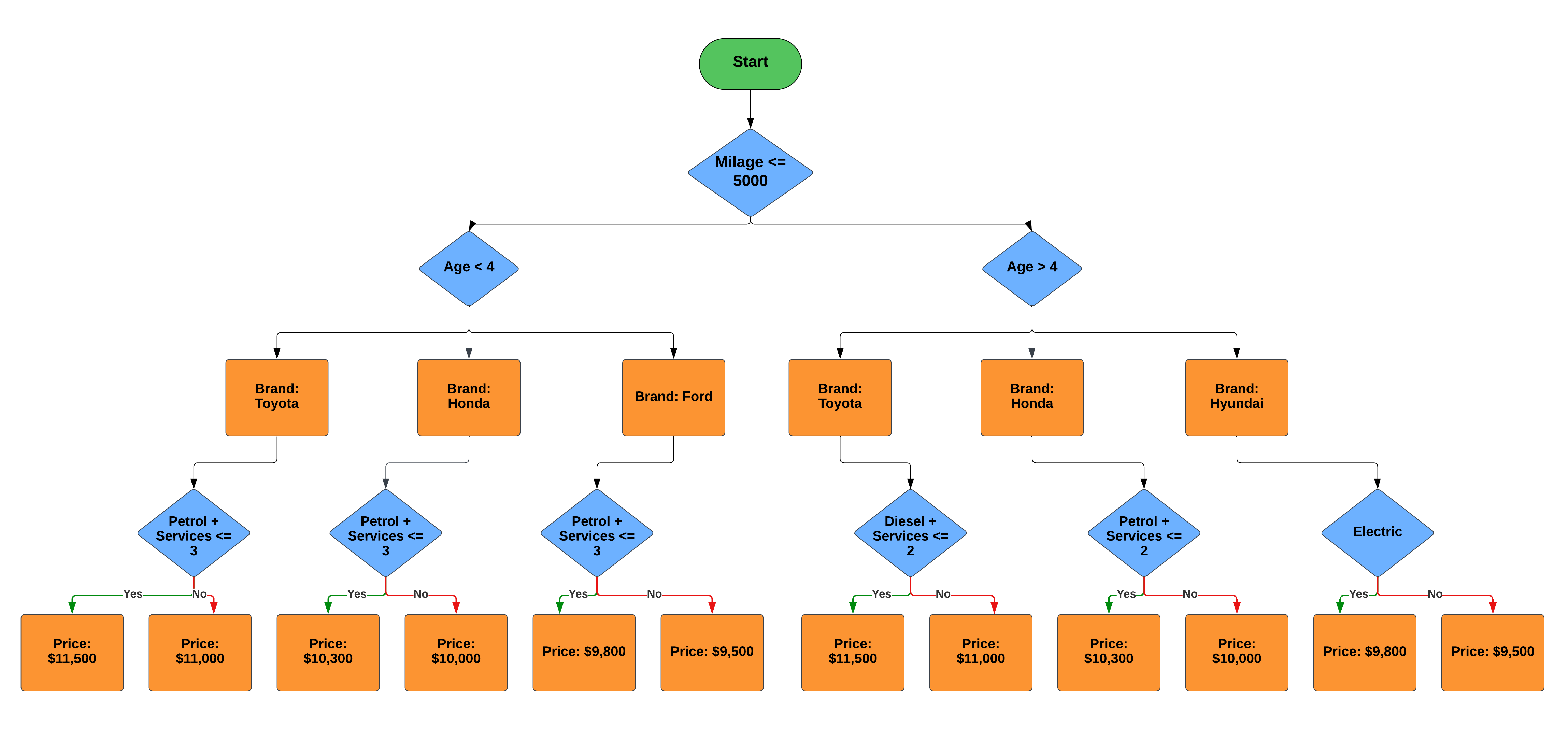
The Constructed Regression Decision Tree:
The resulting regression decision tree would look like a hierarchical structure with nodes and branches. Each leaf node contains a predicted price value.
Making Predictions:
To predict the price of a new second-hand car, you traverse the decision tree starting from the root node, following branches based on the features of the car. When you reach a leaf node, the value assigned to that leaf node is the predicted price for the car.
Overfitting issue with Decision Tree:
Overfitting occurs when a machine learning model, such as a decision tree, captures noise and random fluctuations in the training data rather than the underlying patterns in the data. This leads to a model that performs very well on the training data but poorly on new, unseen data because it has essentially memorized the training data rather than learned generalizable patterns.
In the above structure, if we consider the branch for "Brand:
Ford" when "Age <= 4" and "Diesel + Services <= 1," we have a rule that specifies a price of $9,500. This rule may fit the training data well, but it might not be a robust representation of the actual price for Ford cars in similar situations.
Now, consider a real-world scenario where you have a Ford car that is 3 years old, has low mileage, runs on diesel, and has had only one service. According to the decision tree, the predicted price is $9,500 based on the specific conditions it has learned. However, in reality, there could be various factors affecting the price that the decision tree has not considered.
This is an example of overfitting because the decision tree has created overly complex and specific rules for certain conditions in the training data, which may not generalize well to unseen data. To mitigate overfitting, you can
1. Limit the maximum depth of the decision tree.
2. Set a minimum number of samples required to split a node.
3. Use pruning techniques to remove branches that do not contribute significantly to the model's performance.
By controlling the complexity of the decision tree, you can build a more robust and generalizable model.
Applying the techniques of "Limiting the Maximum Depth" and "Minimum Samples per Leaf":
To overcome overfitting in the decision tree model for your problem of "Pricing Detection for Secondhand Cars," you can apply the techniques of "Limiting the Maximum Depth" and "Minimum Samples per Leaf".
Now, let's apply the two techniques (Limiting Maximum Depth and Minimum Samples per Leaf) to overcome overfitting.
Limiting Maximum Depth:
We limit the maximum depth of the tree to 2 levels below the root node.
Minimum Samples per Leaf:
We set the minimum number of samples required to create a leaf node to 5.
Modified Decision Tree (After Applying Techniques):
This is the After Applying Techniques black diagram.
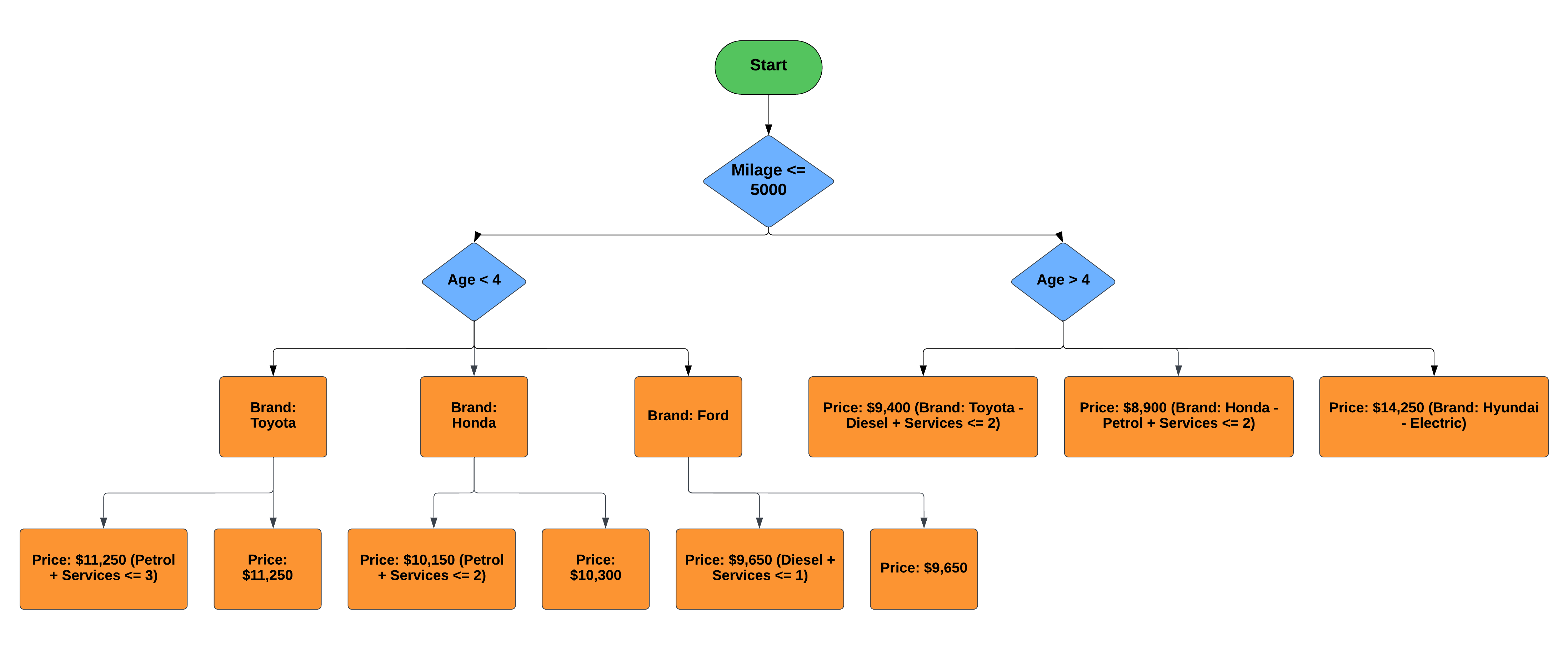
let's provide specific examples for the "Impact" and "Improved Prediction" sections based on the decision tree modifications for pricing second hand cars.
Impact - Simpler Decision Tree:
Original Decision Tree - The original decision tree had multiple branches and complex conditions.
Modified Decision Tree - After simplification, the tree becomes more straightforward to interpret.
Example:
In the original tree, there were specific branches for "Petrol + Services" and "Diesel + Services," making it challenging to follow. In the modified tree, these branches are simplified, resulting in a clearer structure.
Broader Categories for Predictions:
Original Decision Tree - The original tree made predictions based on fine-grained combinations of age, brand, and services.
Modified Decision Tree - The simplified tree predicts based on broader categories.
Example:
In the original tree, a specific prediction might be made for a 4-year-old Toyota with "Petrol + Services" and 45,000 km mileage. In the modified tree, this car falls into a broader category, making predictions based on age and brand, resulting in a more generalized estimate.
Reduced Overfitting:
Original Decision Tree - The original tree was prone to overfitting due to its complexity.
Modified Decision Tree - The simplified model is less prone to overfitting.
Example:
The original tree could make overly specific predictions for cars with rare combinations of features, which might not represent the overall market. The modified tree avoids such overfitting by capturing general pricing trends.
Improved Prediction - Less Specific Predictions:
Original Decision Tree - The original tree might make very specific predictions for cars with minor variations.
Improved Prediction - The modified tree provides more generalized predictions.
Example:
If you have a 4-year-old Honda with "Petrol + Services" and 47,000 km mileage, the original tree might predict a highly specific price. In contrast, the modified tree, by considering broader categories, predicts a more reasonable price based on age and brand.
Better Generalization:
Original Decision Tree - The original tree struggled to generalize to new, unseen cars.
Improved Prediction - The modified tree is more effective at generalizing.
Example:
Suppose you input data for a secondhand car that the model hasn't seen before, such as a 5-year-old Hyundai with "Electric" power and 60,000 km mileage. The modified tree is less likely to make an overly specific prediction and will provide a more accurate estimate based on similar categories in the training data.
In these examples, the impact and improved prediction sections demonstrate how the modifications to the decision tree structure result in more general, accurate, and robust predictions for secondhand car prices.
Conclusion:
In this blog post, we explored the concept of overfitting in decision trees and demonstrated how limiting maximum depth and setting a minimum number of samples per leaf can mitigate this issue. By applying these techniques, we simplified the decision tree, making it more interpretable and improving its predictive capabilities for secondhand car prices.Decision trees are a powerful tool, but understanding how to optimize them is crucial to harness their true potential in predictive modeling. Happy modeling!